LLM Extract Node
The LLM Extract node in BuildShip allows you to easily scrape and extract structured data from any webpage using your favorite LLMs such as GPT from OpenAI or claude from Anthropic. The LLM Extract node will take care of all the data massaging, such as removing unnecessary content and returning the data in a well-structured and consistent format
OpenAI - LLM Extract
The OpenAI LLM Extract node uses GPT to extract structured data from any webpage. The node accepts the following inputs:
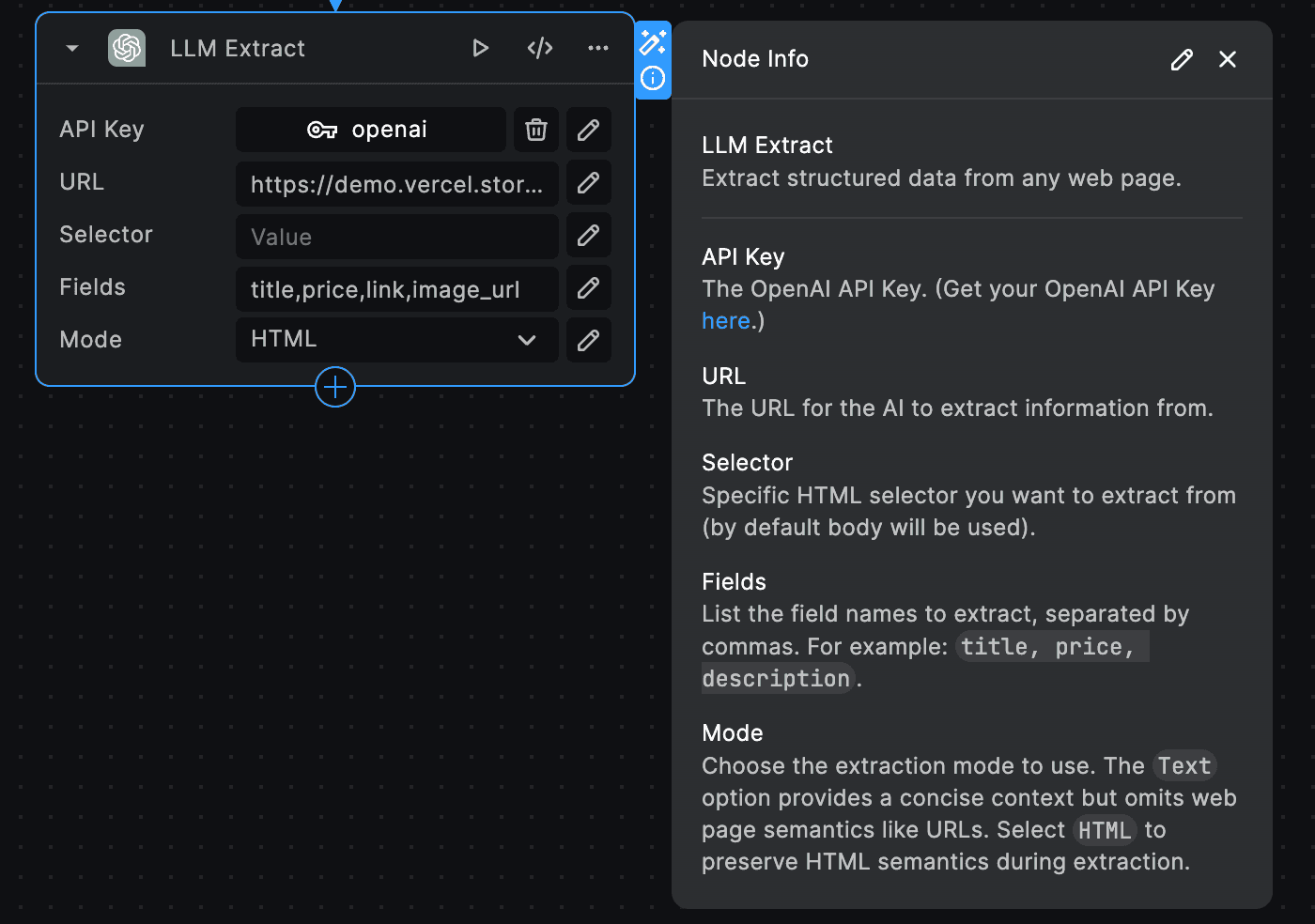
- API key (required): Your OpenAI API Key. (Get your OpenAI API Key here (opens in a new tab))
- URL (required): The URL for the AI to extract information from.
- Selector (optional): The specific HTML selector you want to extract from (by default body will be used).
- Fields (required): The field names to extract, separated by commas. For example:
title, price, description. The LLM will try to use the field names you enter to identify and extract the data you're interested in. So, it’s important to be precise and clear when naming these fields to ensure accurate data extraction - Mode (required): The extraction mode to use. The
Textoption provides a concise context but omits web page semantics like URLs. SelectHTMLto preserve HTML semantics such as page link and image urls during extraction.
Anthropic - LLM Extract
The Anthropic LLM Extract node uses Claude to extract structured data from any webpage. The node accepts the following inputs:
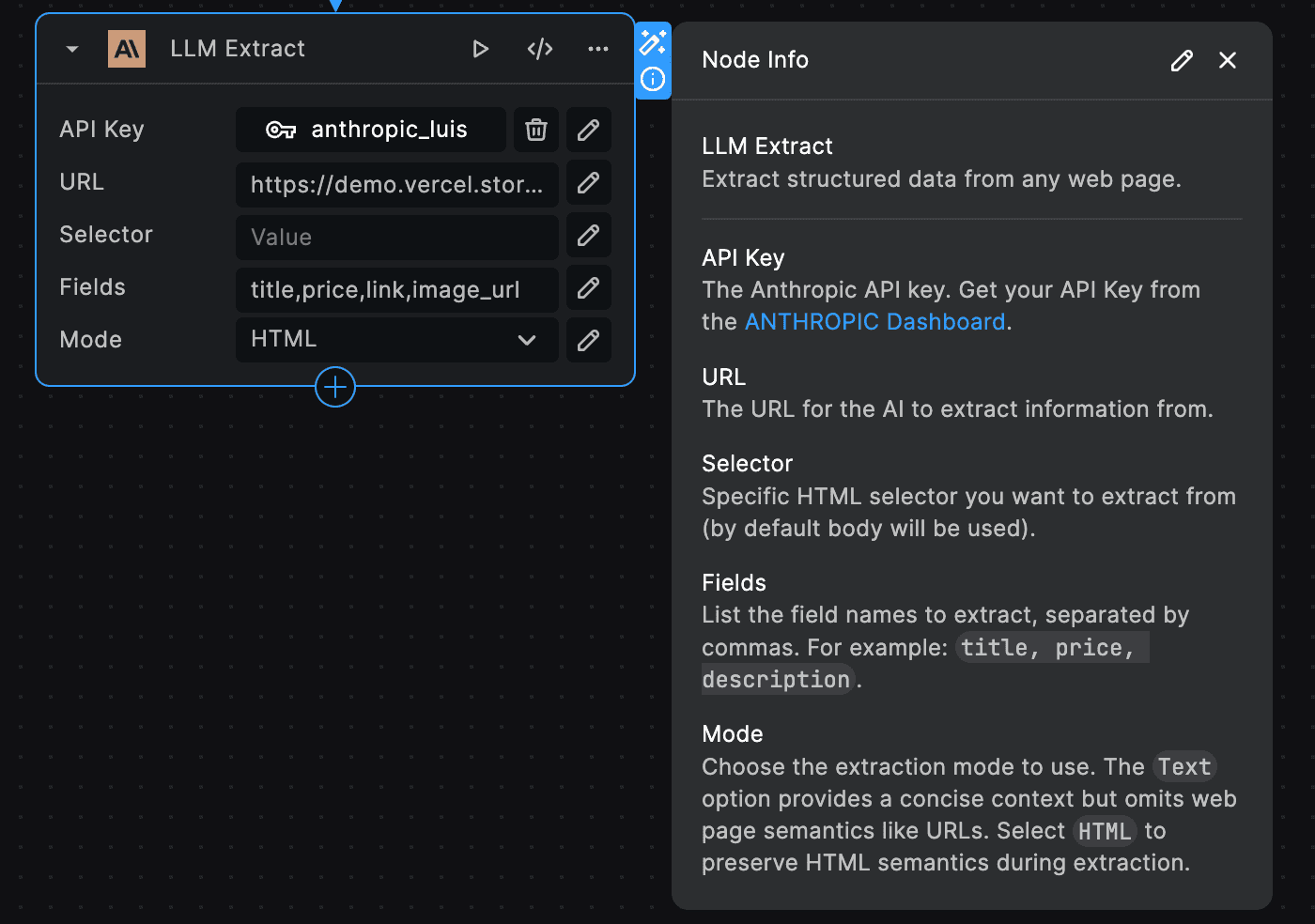
- API key (required): Your Anthropic API Key. (Get your Anthropic API Key here (opens in a new tab))
- URL (required): The URL for the AI to extract information from.
- Selector (optional): The specific HTML selector you want to extract from (by default body will be used).
- Fields (required): The field names to extract, separated by commas. For example:
title, price, description. The LLM will try to use the field names you enter to identify and extract the data you're interested in. So, it’s important to be precise and clear when naming these fields to ensure accurate data extraction - Mode (required): The extraction mode to use. The
Textoption provides a concise context but omits web page semantics like URLs. SelectHTMLto preserve HTML semantics such as page link and image urls during extraction.
Node Outputs
Both the OpenAI and Anthropic LLM Extract nodes return the extracted data in an array. Each item in the array contains the extracted fields as key-value pairs.
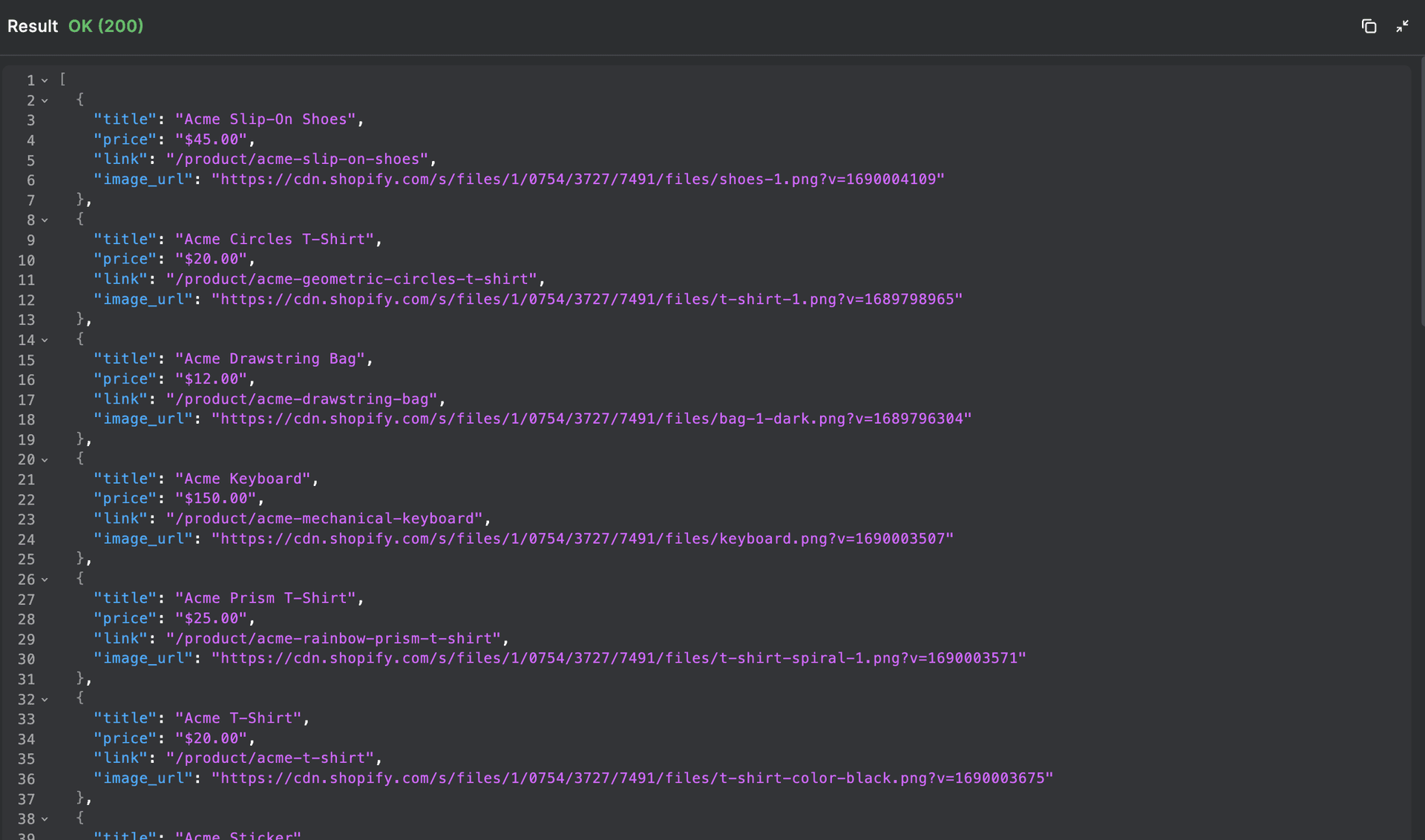
Testing the LLM Extract Node
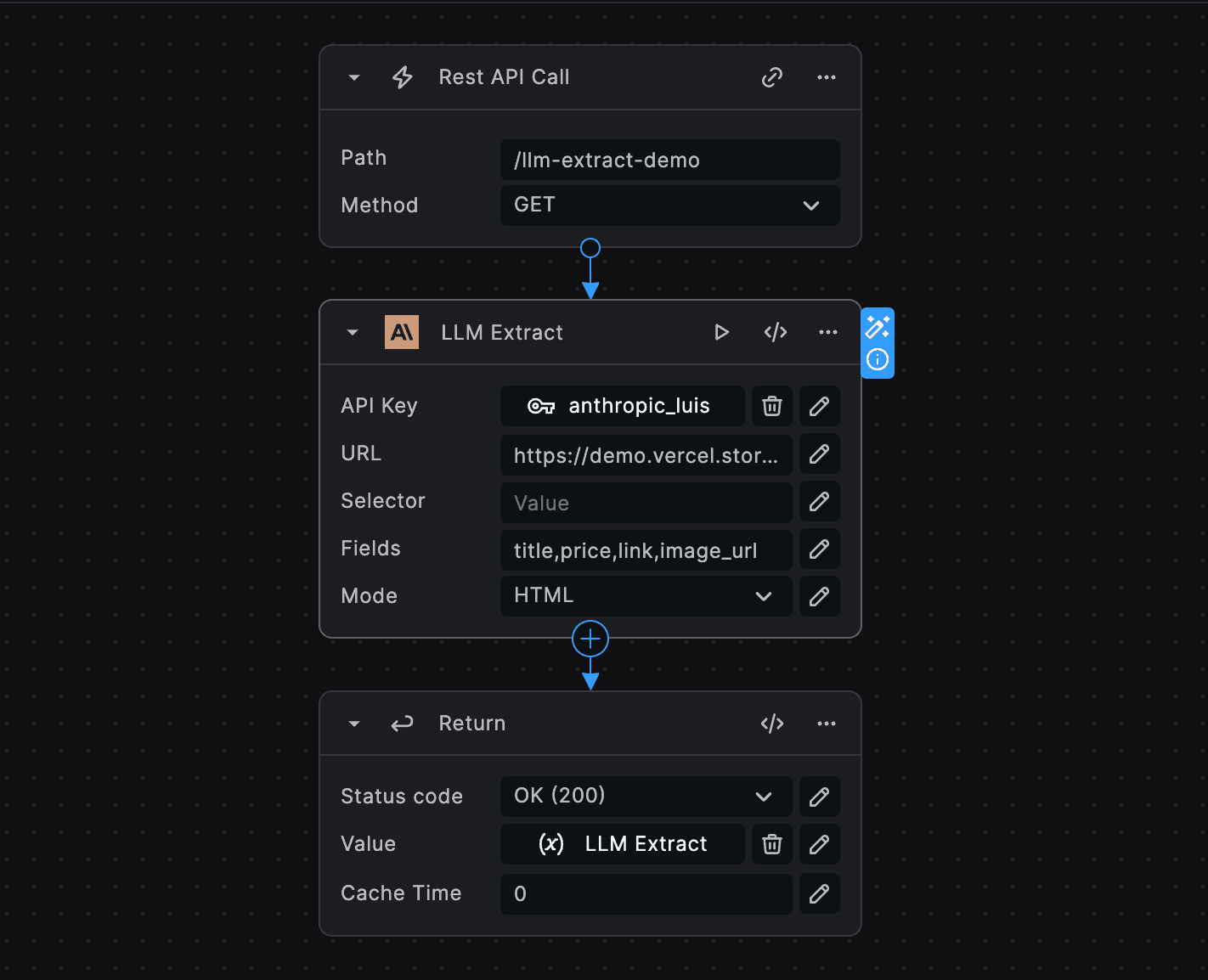
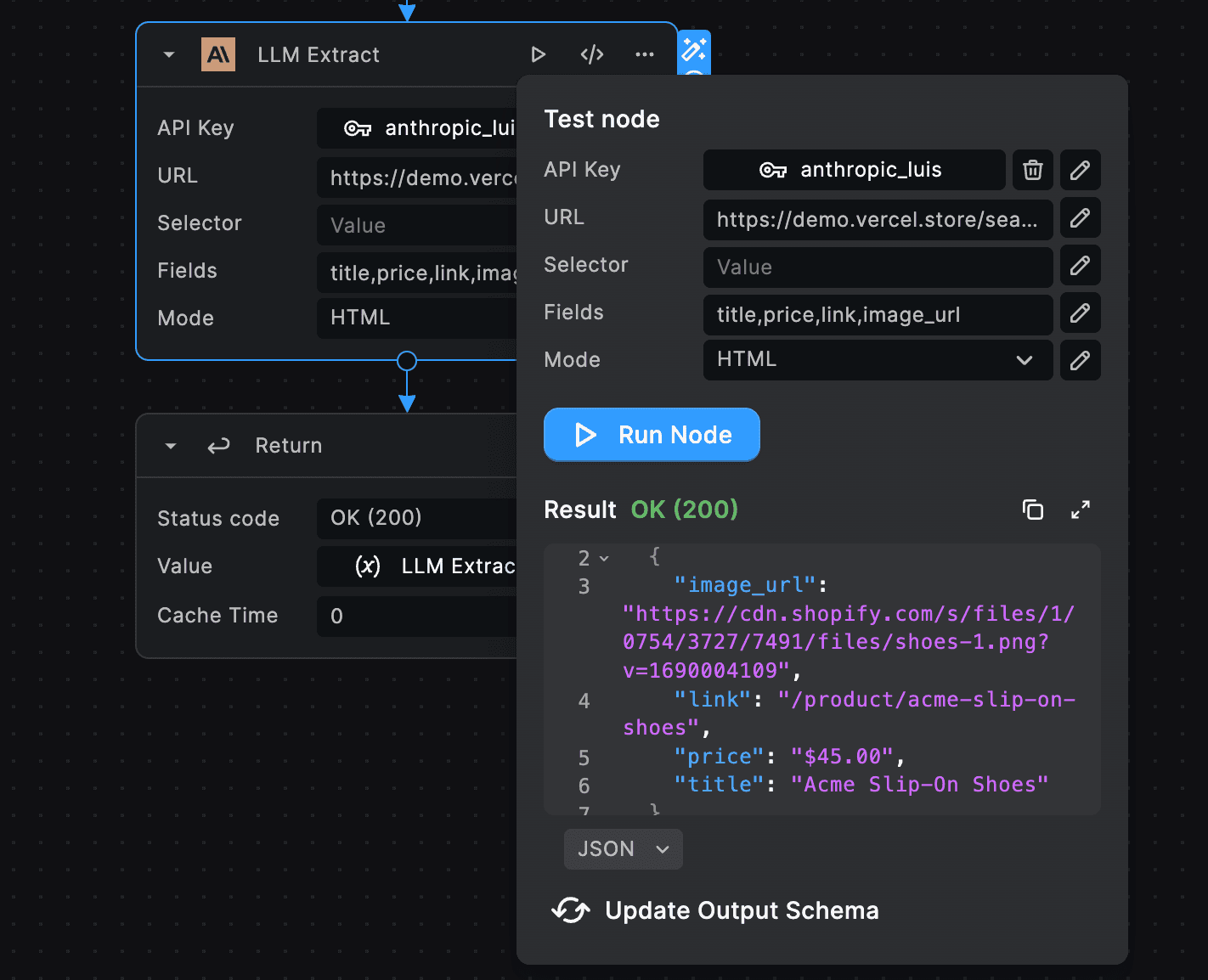
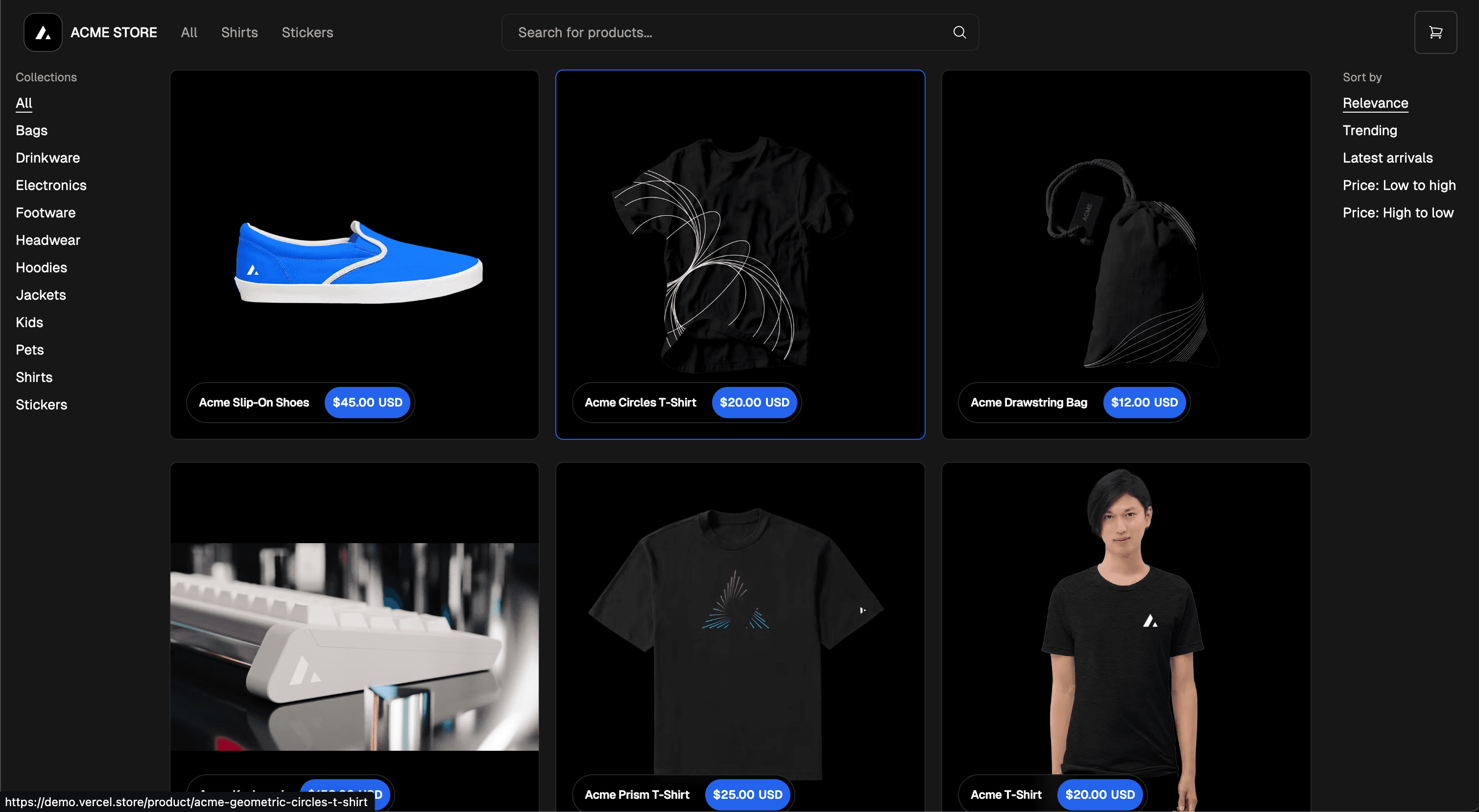
Imagine you want to extract the title, price, link, and image url from this ecommerce website. You can find the live ecommerce site here (opens in a new tab).
For this we'll use the OpenAI LLM Extract node. We'll set the url to https://demo.vercel.store/search, the fields to
title, price, link, image, and the mode to HTML.
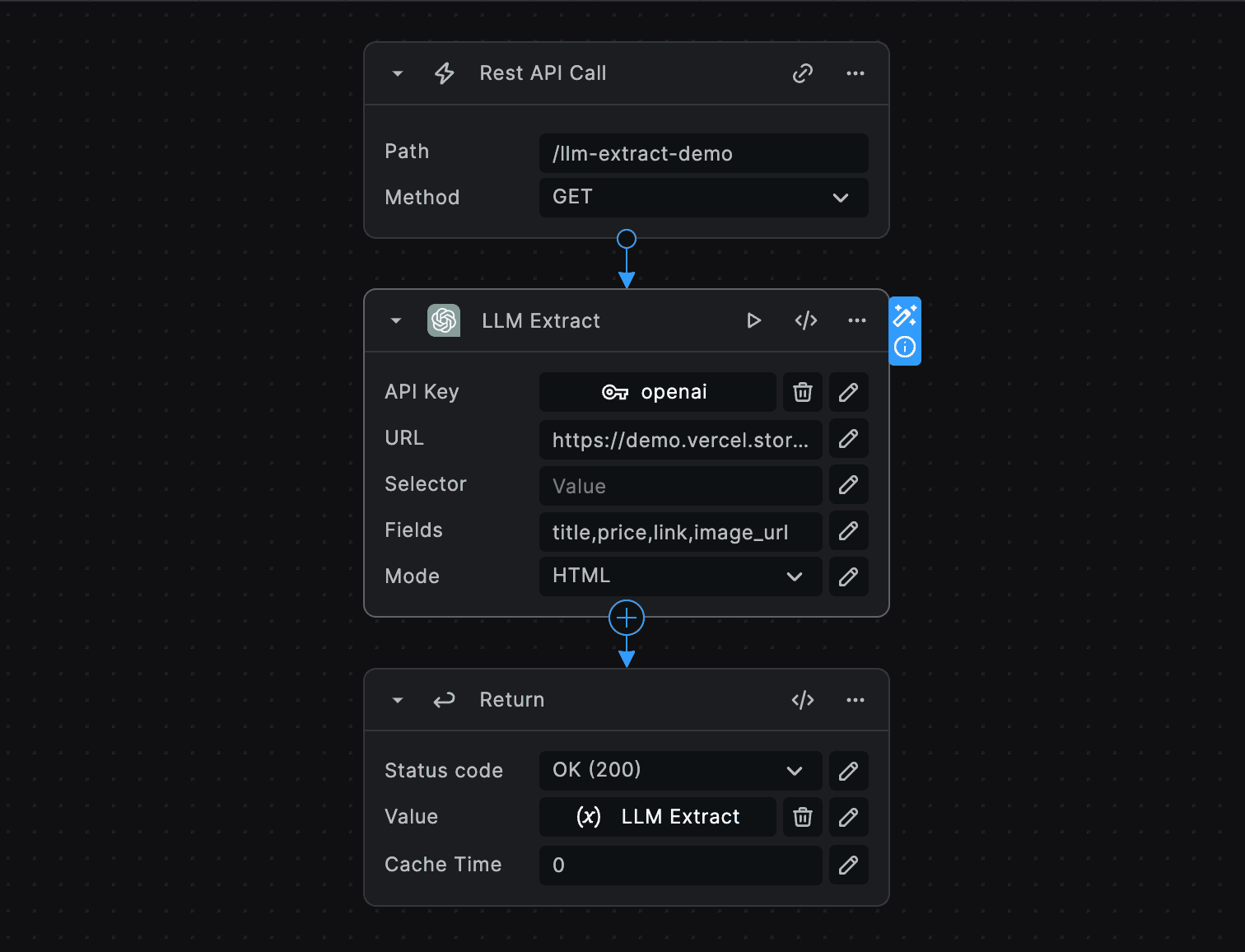
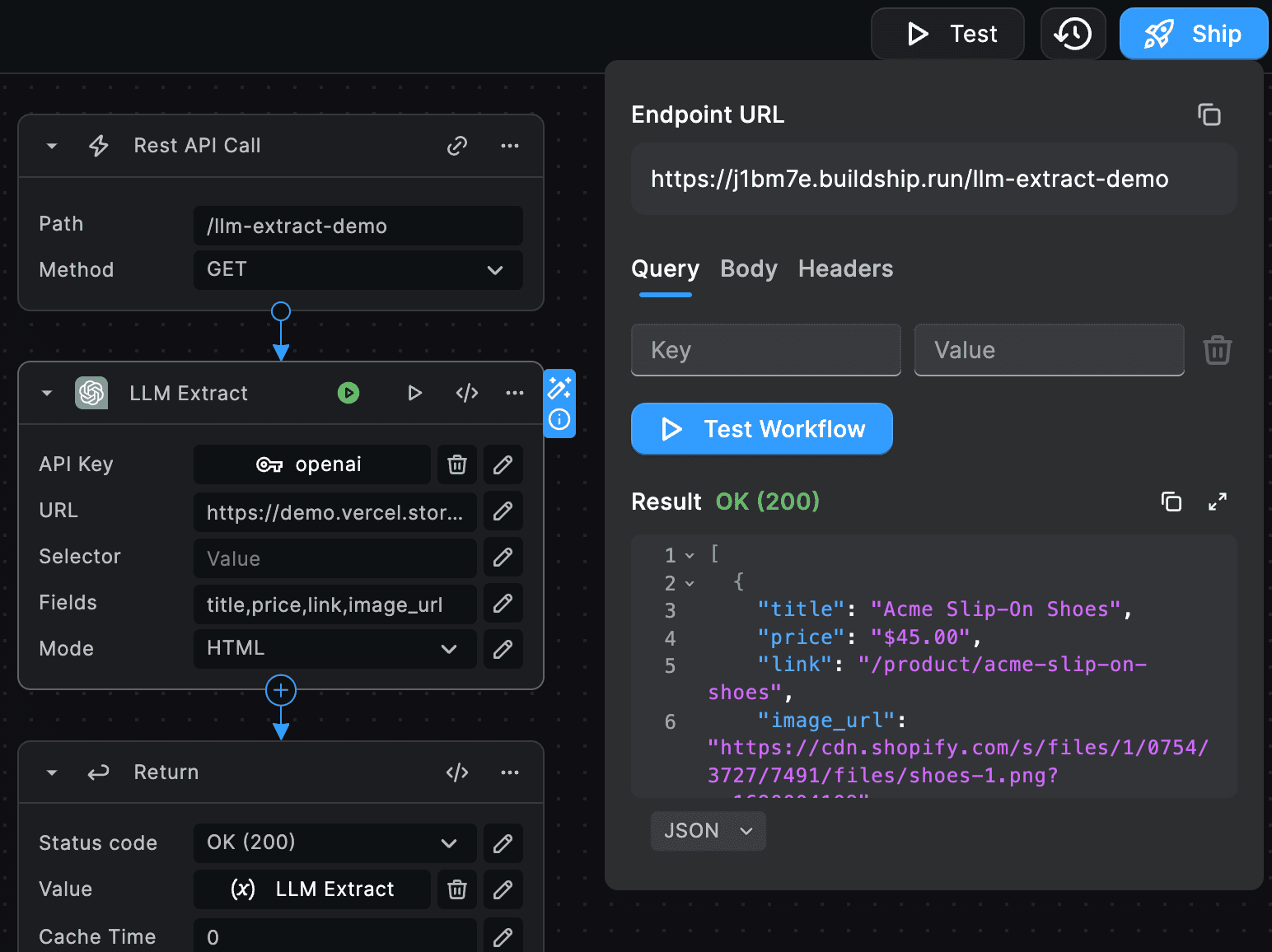
And after using BuildShip's inbuilt testing feature, we get back the extracted data in a well-structured format from the ecommerce website.
Some current limitations of the LLM Extract node include its inability to handle infinite scroll or pagination, and the potential for running into token limits (depending on the LLM you're using) when extracting data from a large number of pages
Need Help?
- 💬Join BuildShip Community
An active and large community of no-code / low-code builders. Ask questions, share feedback, showcase your project and connect with other BuildShip enthusiasts.
- 🙋Hire a BuildShip Expert
Need personalized help to build your product fast? Browse and hire from a range of independent freelancers, agencies and builders - all well versed with BuildShip.
- 🛟Send a Support Request
Got a specific question on your workflows / project or want to report a bug? Send a us a request using the "Support" button directly from your BuildShip Dashboard.
- ⭐️Feature Request
Something missing in BuildShip for you? Share on the #FeatureRequest channel on Discord. Also browse and cast your votes on other feature requests.